Federation Architecture Overview
May 5, 2023
by The Bluesky Team
Many of our experiences with social media today are defined by the same constraining dynamics — one private company owns all of our data, populates our feeds with an algorithm of their choice, and we’re unable to take our followers and posts with us to a new home if we ever decide to leave. The AT Protocol, a federated networking model which Bluesky is built upon, changes this.
Soon, we’re launching a sandbox environment to begin the testing phase of federation for the AT Protocol with allow-listed servers. In advance of this launch, we want to share some technical details about our design decisions with you.
At a high level, federation means that anyone can run the parts that make up the AT Protocol themselves, such as their own server. Sandbox mode means that people can start experimenting with federation without interfacing with the actual network — think of it as a test network. If you’d like to run your own server, you’ll be able to do so in the near future.
Update: Join the atproto federation developer sandbox here!
Federation Architecture
The AT Protocol is made up of a bunch of pieces that stack together. (Technically, the lower-level primitives that can get stacked together differently are the repositories, lexicons, and DIDs.) This means that the architecture we’re proposing for launching federation is not the only network architecture that’s possible – it’s just what we expect to be the most powerful and robust way of supporting public conversations on a global social network, so we implemented it first.
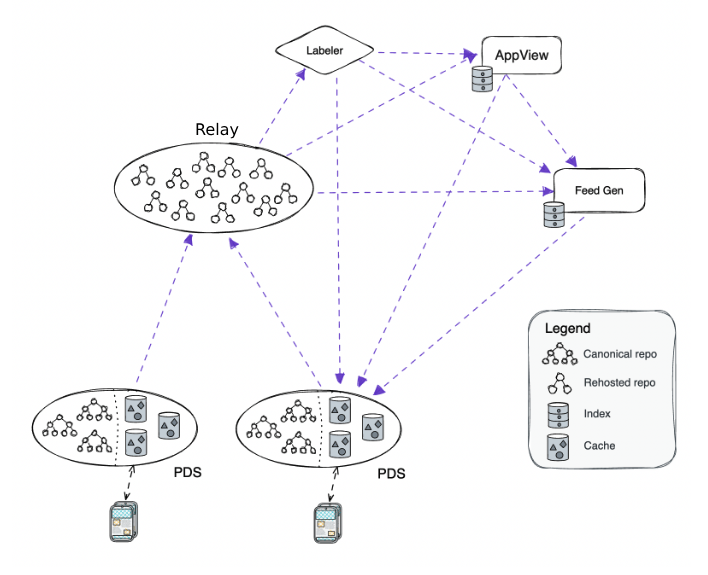
The three main services of our first federation are personal data servers (PDS), relays, and App Views. Developers can also run feed generators (custom feeds), and labelers are in active development.
- Personal Data Server (PDS)
- A PDS acts as the participant’s agent in the network. This is what hosts your data (like the posts you’ve created) in your repo. It also handles your account & login, manages your repo’s signing key, stores any of your private data (like which accounts you have muted), and handles the services you talk to for any request.
- Relay
- The Relay handles "big-world" networking. It crawls the network, gathering as much data as it can, and outputs it in one big stream for other services to use. It’s analogous to a firehose provider or a super-powered relay node.
- App Views
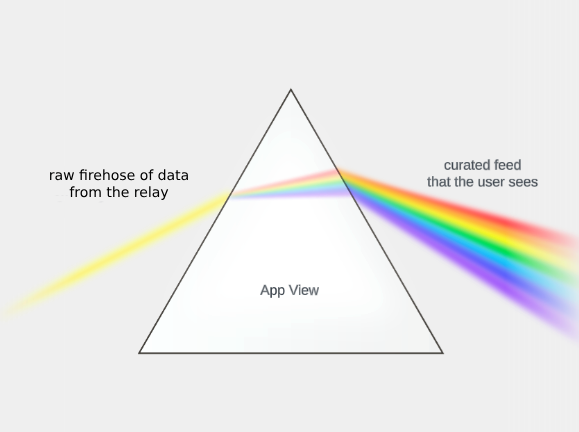
- An App View is the piece that actually assembles your feed and all the other data you see in the app, and is generally expected to be downstream from a Relay's firehose of data. This is a highly semantically-aware service that produces aggregations across the network and views over some subset of the network. This is analogous to a prism that takes in the Relay's raw firehose of data from the network, and outputs views that enable an app to show a curated feed to a user. For example, the Relay might crawl to grab data such as a certain post’s likes and reposts, and the app view will output the count of those metrics.
The federation architecture allows anyone to host a Relay, though it’s a fairly resource-demanding service. In all likelihood, there may be a few large full-network providers, and then a long tail of partial-network providers. Small bespoke Relays could also service tightly or well-defined slices of the network, like a specific new application or a small community.
There will also be an ecosystem of App Views for each lexicon, or “social mode,” deployed on the network. For example, Bluesky currently supports a micro-blogging mode: the app.bsky lexicon. Developers who create new lexicons would likely deploy a corresponding App View that understands their lexicon to service their users. Other lexicons could include video or long-form blogging, or different ways of organizing like groups and forums. By bootstrapping off of an existing Relay, data collation will already be taken care of for these new applications. They need only provide the indexing behaviors necessary for their application.
“Big World” Design
When we were architecting the topology of the AT Protocol, we looked at the web as an example. We see the web as the most successful decentralized system in existence — millions of devices globally connected on an open network — so we’re taking it as a null hypothesis of what works best.
As a result, we opted to architect the protocol in a “big world with small world fallbacks” way. With the web, individual computers upload content to the network, and then all of that content is then broadcasted back to other computers. Similarly, with the AT Protocol, we’re sending messages to a much smaller number of big aggregators, which then broadcast that data to personal data servers across the network. Additionally, we solve the major problems that have surfaced from the web through self-certifying data, open schematic data and APIs, and account portability.
On a technical level, prioritizing big-world indexing over small world networking has multiple benefits.
- It significantly reduces the load on PDSs, making it easier to self-host — you could easily run your own server.
- It improves discoverability of content outside of your immediate neighbors — people want to use social media to see content from outside of their network.
- It improves the quality of experience for everyone in the network — fewer dropped messages or out-of-sync metrics.
Given all that, our proposed methodology here of networking through Relays instead of server-to-server isn’t prescriptive. The protocol is actually explicitly designed to work both ways.
What’s Next For Us
We strongly believe that for federation to matter, all the pieces must be easy for you to set up. When we launch our sandbox environment publicly, we’ll provide straightforward instructions.
Meanwhile, we’re working on two more pieces of federation: feed generators and labelers. Currently, Bluesky’s App View generates some “opinionated” data (as in, it differentiates between pieces of data, unlike a giant firehose of data), like the feeds that we show users and the labels we use in content moderation. But we’re experimenting with splitting feed generators and labelers out as services of their own, and when that’s complete, anyone may host a feed generator and advertise it to users in the marketplace of algorithms.
From a technical perspective, here’s one potential architecture: A feed generator can exist downstream of some Relay and App View, where the feed generator is constrained to offering “candidates” for the feed. Then, the App View presents the actual view of that data to the user.
Similarly, a labeler would also be downstream of a Relay. Its labels would then be ingested by either an App View or a semantically-aware PDS.
Sandbox Mode
We will be initially launching federation in sandbox mode with allow-listed servers. This means we’ll be running it in a staging environment that gets reset at least once a week, allowing the network to test it out before going live with all existing user data. Having a sandbox environment is very useful, as it will allow us and all developers in the ecosystem to stress-test and debug the system. The sandbox environment we’ve set up can be used to test out future major protocol changes as well. You can participate in the sandbox as a developer or a user — just be aware that things will break, and your data will get wiped!
The sandbox environment is also useful to us as we finish building out our moderation and curation tooling. Before we open federation entirely, we want to provide other servers with the same toolbox that we’re using to curate a safe social media experience, and developers can also build more moderation tools on top of atproto themselves.
We’ll be sharing more soon about moderation, and about how to start experimenting with the sandbox environment.